
Architecture
CBOW consists of:
- Input Layer – Context words (one-hot vectors)
- Hidden Layer (Embedding Layer) – Dense embeddings
- Output Layer – Target word prediction
Two weight matrices:
- W₁ (Input → Hidden) of size V × N
- W₂ (Hidden → Output) of size N × V
Where:
- V = Vocabulary size
- N = Embedding dimension
Weight Matrix W₁ (Input → Hidden)
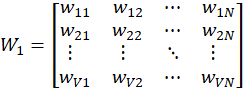
Each row represents embedding of one word.
Embedding Lookup
For a one-hot input word
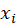
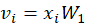
This simply selects:
vi=[wi1,wi2,…,wiN]
For k context words:
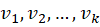
Context Aggregation
CBOW averages all embeddings:
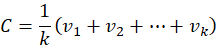
This produces a single context vector C.
Weight Matrix W₂ (Hidden → Output)
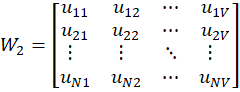
Output Computation
Context vector multiplied with W₂:
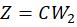
This gives:
Z=[z1,z2,…,zV]
Raw scores for all vocabulary words.
Softmax
(Softmax:
- Takes raw scores z1,z2,…,zVz_1, z_2, …, z_Vz1,z2,…,zV
- Converts them to exponentials
- Divides each by total sum
- Produces probabilities between 0 and 1
- All probabilities sum to 1
)
Softmax converts scores into probabilities:
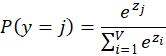
→ raw score
→ vocabulary size
 → probability of j-th word
→ probability of j-th word
Denominator → normalization
The word with highest probability is predicted.
Loss Calculation
Cross-entropy loss: L=−log(P(ytrue))
Backpropagation
Error is propagated backward to update:
- W₂ (hidden → output)
- W₁ (input → hidden / embeddings)
Repeat
Process is repeated for:
- all sliding windows
- all sentences
- multiple epochs