
Do you think a computer can create a human face that doesn’t exist?
In 2014, AI could only generate blurry black-and-white faces…
But by 2018, it started generating realistic human faces.

Left → blurry images
Right → realistic face
What changed in these 4–5 years?
Did the computer suddenly become intelligent?
This improvement happened because of a special model called GAN — Generative Adversarial Network.

These faces look real 👀
But they are completely fake
Earlier we saw blurry images in 2014…
Now AI can create this level of realistic faces.
So how did AI become so powerful?
How is it learning to create such realistic images?
This happens because of a model called GAN
Let’s understand how AI is able to generate such realistic images… using GAN.
Understanding GAN Architecture (From Basics to Training & Fine-Tuning)
What is GAN?
Generative Adversarial Network
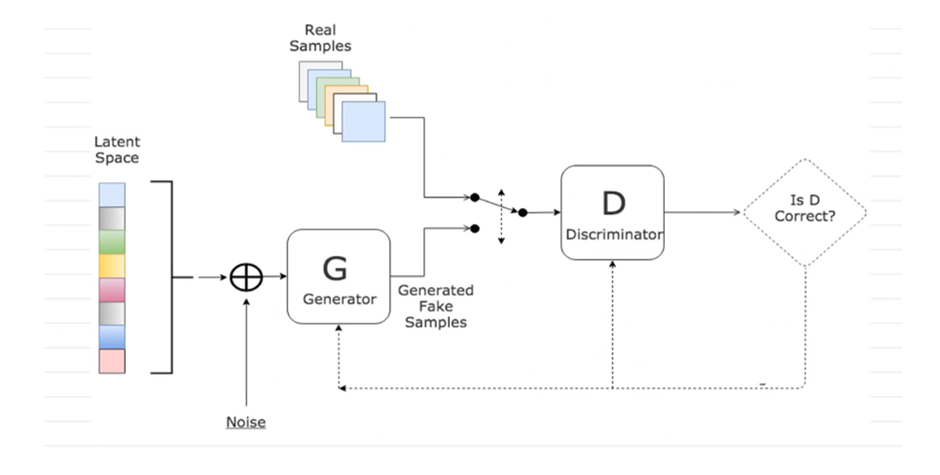
As shown in a diagram,
A GAN (Generative Adversarial Network) consists of two neural networks:
🔹 Generator (G)
- Creates fake data (e.g., images)
🔹 Discriminator (D)
- Checks whether data is real or fake
In GAN, we have two players.
- Generator → creates fake images
- Discriminator → checks real vs fake
“Generator tries to make fake images look real,
and Discriminator tries to catch them.”
Analogy
👉 “Like a student copying art… and a teacher checking it.”
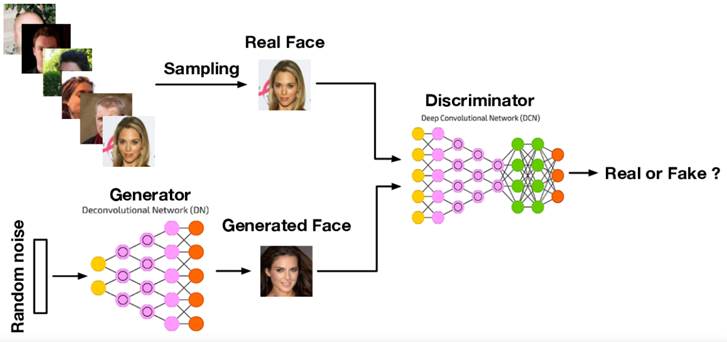
Generator at beginning
As shown in an image,


Initially, Generator has NO idea what to create.”
- Output = random, messy drawing
It doesn’t know what a real image should look like.
At start, Generator is very bad.
Discriminator learning
Discriminator sees real images and fake images.
What does Discriminator get?
- Real images → labeled as REAL
- Fake images → labeled as FAKE
Discriminator is trained like a classifier.
Real image → correct answer = REAL
Fake image → correct answer = FAKE
That is,
Discriminator gets BOTH:
- Image ✔
- Label (REAL / FAKE) ✔
But here is the IMPORTANT part
👉 It gets:
- Image → as input
- Label → as feedback (correct answer)
Step-by-step (very simple)
Step 1: Input comes
👉 Discriminator gets:
- Image
👉 It predicts:
- “REAL” or “FAKE”
Now label is used
👉 We already know the correct answer:
- Real image → REAL
- Generated image → FAKE
👉 This correct answer = Label
Step 3: Compare
We check:
| Prediction | Label | Result |
| REAL | REAL | Correct ✅ |
| FAKE | REAL | Wrong ❌ |
Step 4: Feedback (THIS is important)
👉 If wrong:
- Error is calculated
- Model is told:
“You made a mistake”
👉 This is called feedback
Step 5: Update Weights
👉 Now model adjusts its internal parameters(like weights and bias):
What does “update weights” mean?
👉 Small changes are made inside the network:
- Increase some weights
- Decrease some weights
👉 So next time:
- Prediction becomes better
Step 6: Repeat
👉 This process repeats many times:
- Again input
- Again prediction
- Again feedback
- Again update
👉 This is called:
Training loop
At first, Discriminator guesses randomly.
👉 Sometimes right
👉 Sometimes wrong
When Discriminator makes mistake:
It gets error (feedback)
It updates its weights
Discriminator learns by correcting its mistakes.
Improvement over time
- Initially → 50% accuracy (random guessing)
- Then → 60%
- Then → 80%
👉 It becomes better at detecting fake
As Discriminator becomes stronger, Generator has to improve more.
The Game Begins
Now the game starts between Generator and Discriminator.
Generator creates fake image
Discriminator gives score (how real it looks)

Example:
- 5% real → very bad
- 40% real → slightly better
Generator improves
Generator learns from mistakes.
“Okay, that didn’t work… let me try something better.”
This is where TRAINING happens.
Over time, Generator improves more and more.”
- 30% → looks fake
- 60% → looks somewhat real
- 95% → almost real
So, How Generator Learns
- Creates fake image
- Discriminator rejects it
- Gets feedback (error)
- Improves
👉 Learns to create more realistic images
How Discriminator Learns (VERY IMPORTANT)
Discriminator is trained like a classifier:
It receives:
- Real image → label = REAL
- Fake image → label = FAKE
Learning process:
- Makes prediction
- Compares with correct answer
- Calculates error
- Updates weights
The GAN Game (Training Loop)
Training happens like a game:
- Generator creates fake image
- Discriminator checks it
- Gives feedback
- Both update weights
- Repeat many times
Result Over Time
- Generator → creates realistic images
- Discriminator → becomes better at detection
👉 Both improve together
Key Concept of Training
Training in GAN means updating weights of Generator and Discriminator repeatedly using feedback.
Now our GAN is fully trained — Generator creates realistic images and Discriminator is very strong.
What if I want something specific?
Examples:
- Only cartoon faces
- Only animal images
- Only medical images
👉 Say:
“Our model is trained, but it is general. What if we want specialization?”
So, there is a need of Fine-tuning
Fine-tuning means taking an already trained model and slightly improving it for a specific task.
During training, we updated weights from scratch.
In fine-tuning, we don’t start from zero — we just adjust weights slightly.
👉 “Our GAN generates human faces.”
Now we want:
👉 “Only cartoon faces”
- We take trained GAN
- Give new dataset (cartoons)
- Train for few iterations
- Slightly update weights
👉 This is fine-tuning
| Training | Fine-tuning |
| Starts from scratch | Starts from trained model |
| Large data | Small specific data |
| Big changes in weights | Small changes |
Important clarification
“Weights are updated in both training and fine-tuning — but the difference is WHEN and HOW MUCH.”
Fine-tuning is the process of slightly adjusting the weights of a pre-trained model using specific data to make it suitable for a particular task.